이 글은 "쿠버네티스 교과서 | 엘튼 스톤맨"의 책의 내용을 참고하여 작성됨을 알립니다.
쿠버네티스에서 “데이터가 남는다”는 말은 결국 파드/컨테이너가 재시작/교체되더라도 데이터가 보존되는가의 문제다.
이 장은 그걸 가능하게 만드는 볼륨, 마운트, 영구볼륨(PV), 영구볼륨클레임(PVC), 스토리지클래스(StorageClass)를 다룬다.
1. 컨테이너가 재시작되면 데이터가 사라지는 이유

컨테이너의 파일시스템은 기본적으로 이미지 레이어 + writable layer로 동작한다.
이 구조를 이해하면 “왜 볼륨이 필요한지”가 바로 설명된다.
1-1) killall5로 컨테이너 종료 시키기

killall5는 일반적인 killall이 아니라 리눅스에서 시스템 종료 과정에서 거의 모든 프로세스를 죽이는 명령이다.
- 주로 init, shutdown, reboot 같은 종료 루틴에서 사용됨
- 컨테이너 안에서도 “거의 전체 프로세스 kill”을 수행함
컨테이너는 보통 프로세스 구조가 단순하다.
- PID 1: 컨테이너의 메인 프로세스 (예: sleep)
- 나머지 프로세스: kubectl exec 등으로 잠깐 들어온 프로세스
killall5는 기본적으로
- PID 1을 제외한 모든 프로세스를 죽이거나
- 옵션에 따라 PID 1까지 죽인다
결국 핵심 프로세스인 sleep(PID 1)이 죽으면
- 컨테이너 종료
- Pod 재시작
- containerID 변경
정리하면
- 파드 속 컨테이너 생애주기 = 해당 컨테이너의 생애주기
- 파드의 재시작 = 그 안의 컨테이너 재시작
- 파드 수준에 데이터 저장(볼륨)이 없으면 재시작 시 데이터 유실
2. 컨테이너 파일시스템의 Copy-on-Write(COW)
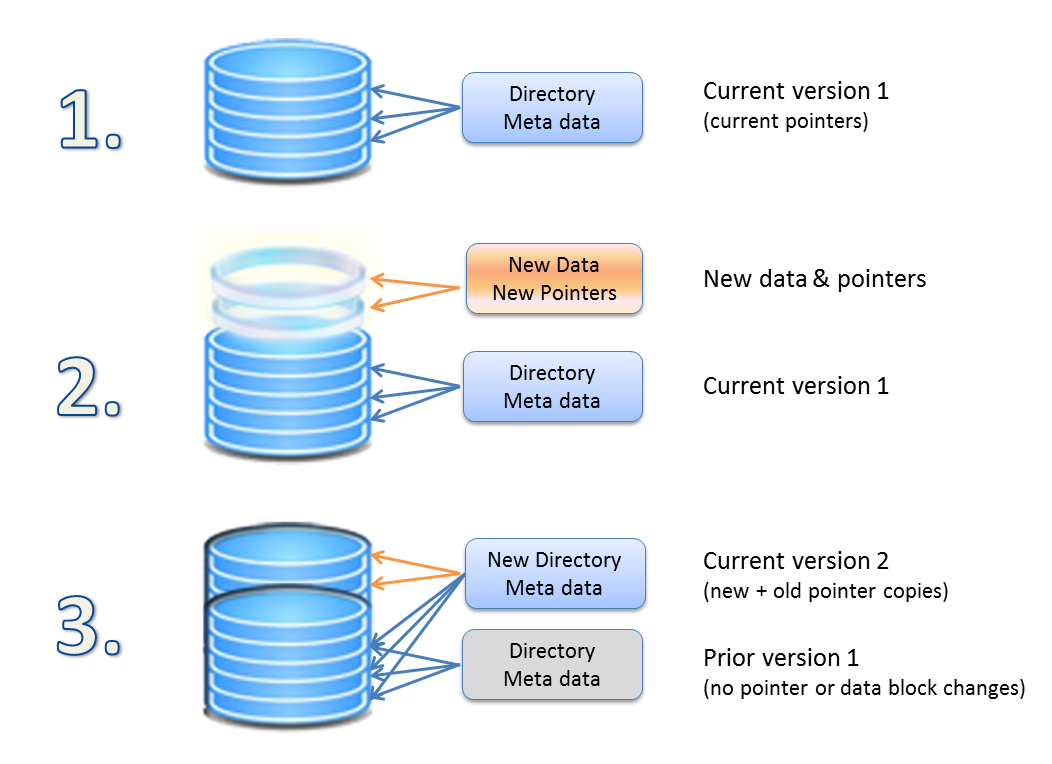
컨테이너 파일시스템의 핵심은 Copy-on-Write 구조다.
- 레이어는 “쌓여 있다”
- 아래: 이미지 레이어들 (read-only)
- 위: writable layer (read-write)
파일을 수정하면
- 아래 레이어 파일을 직접 수정하는 게 아니라
- 위 레이어로 복사한 뒤 수정한다
이걸 Copy-on-Write(COW)라고 부른다.
이 구조 때문에
- 컨테이너가 재시작/교체되면 writable layer는 새로 생성되고
- writable layer에만 있던 데이터는 사라질 수 있다
그래서 파드 수준에서 볼륨을 정의하고 컨테이너 경로에 마운트해야 한다.
3. emptyDir: Pod에 종속되는 임시 볼륨
컨테이너의 파일시스템은 Copy-on-Write 구조이기 때문에,
컨테이너 writable layer에 기록한 데이터는 재시작이나 교체 상황에서 쉽게 유실될 수 있다.
그래서 쿠버네티스는 데이터를 컨테이너가 아니라 Pod 수준에서 관리할 수 있도록
기본 볼륨 타입을 제공하는데, 그 대표적인 예가 emptyDir이다.
3-1) emptyDir의 특징
- Pod가 생성될 때 빈 디렉터리로 시작하고
- Pod가 실행되는 동안만 유지되며
- Pod가 삭제되면 완전히 사라지는 임시 볼륨이다
=> 컨테이너에 종속되는 저장소가 아니라, Pod 생애주기에 종속되는 저장소 - life cycle
- 컨테이너가 죽어도 Pod가 살아있으면 유지되지만
- Pod 자체가 사라지면 emptyDir도 함께 사라진다
3-2) emptyDir이 필요한 이유
Pod 안에는 여러 컨테이너가 동시에 존재할 수 있음.
- Ex1
- initContainer가 파일을 생성하고
- main container가 그 파일을 이어서 사용하는 경우
- Ex2
- 웹 서버가 캐시 데이터를 쓰고
- 사이드카 컨테이너가 이를 공유하는 경우
이때 emptyDir은
- Pod 내부 컨테이너들이 공유할 수 있는 임시 저장 공간을 제공.
3-3) emptyDir YAML 예시
apiVersion: v1
kind: Pod
metadata:
name: cache-pod
spec:
containers:
- name: app
image: nginx
volumeMounts:
- name: cache
mountPath: /cache
volumes:
- name: cache
emptyDir: {}- /cache 경로는 Pod가 유지되는 동안 계속 남아 있다
- Pod가 삭제되면 emptyDir 데이터는 완전히 제거된다
3-4) emptyDir usecases
emptyDir는 영구 데이터 저장 용도가 아니라, Pod 단위의 임시 작업 공간에 적합.
- nginx 캐시 저장소
- 빌드 과정에서 생기는 임시 파일 저장
- 로그 파일을 컨테이너 간 공유
- initContainer → main container 데이터 전달
4. hostPath 볼륨과 subPath 마운트
4-1) hostPath 볼륨의 장단점
hostPath는 노드의 특정 디렉터리를 파드에 연결하는 볼륨이다.
- 장점
- 쿠버로 stateful 앱을 “처음 도입”할 때 빠르게 테스트 가능
- 노드 파일을 직접 확인/생성하는 상황에 좋음
- 한계
- 노드 로컬에 종속됨
- 파드가 다른 노드로 스케줄링되면 데이터 연속성이 깨질 수 있음
또한 hostPath를 노드 전체(root /)로 마운트하면 보안적으로 위험하다.
- 노드 전체에 대해 마운트하면 불필요한 영역까지 노출
- 그래서 보통 하위 디렉터리만 subPath로 제한해서 마운트한다
4-2) subPath로 필요한 경로만 노출하기
spec:
containers:
- name: sleep
image: kiamol/ch03-sleep
volumeMounts:
- name: node-root
mountPath: /pod-logs
subPath: var/log/pods
- name: node-root
mountPath: /container-logs
subPath: var/log/containers
volumes:
- name: node-root
hostPath:
path: /
type: Directory- volumes.hostPath.path: / 로 노드 루트를 잡되
- 실제 컨테이너에 노출하는 건 subPath로 최소화한다
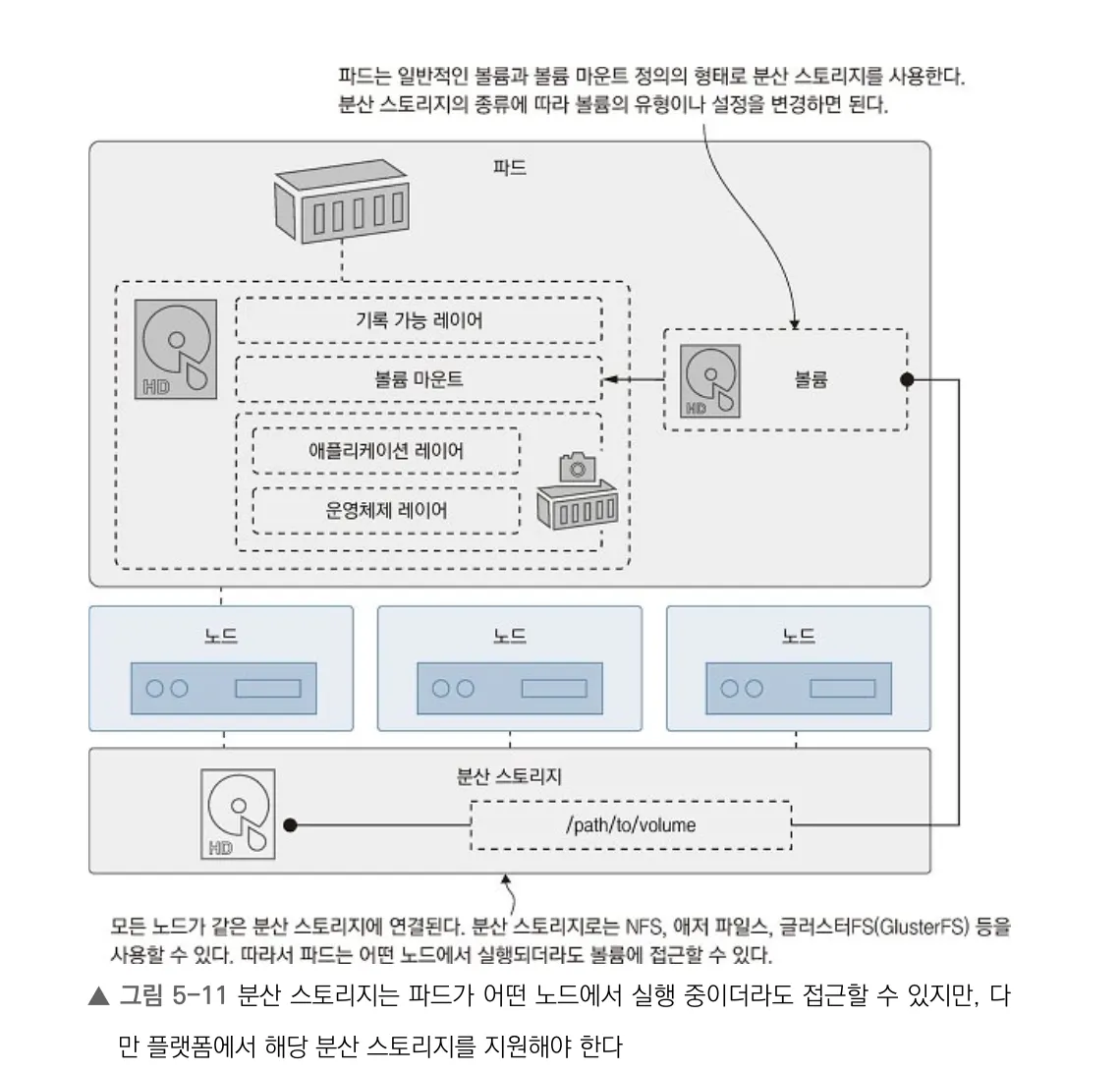
5. PV/PVC: 스토리지 계층의 추상
쿠버네티스에서 계층별 추상화는 이렇게 대응된다.
- Pod: 컴퓨팅 계층의 추상
- Service: 네트워크 계층의 추상
- PV/PVC: 스토리지 계층의 추상
핵심은 파드가 스토리지를 직접 “구현”하지 않고, “요청”만 한다는 점이다.
5- 1) PersistentVolume(PV) 예시: NFS
PV는 “실제 스토리지”를 나타내는 리소스다.
예를 들어 NFS 스토리지 기반 PV는 아래처럼 정의한다.
# 예제 5-5 persistentVolume-nfs.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01
spec:
capacity:
storage: 50Mi
accessModes:
- ReadWriteOnce
nfs:
server: nfs.my.network
path: "/kubernetes-volumes"- PV 용량(capacity)은 “볼륨 자체 크기”
- accessModes는 접근 방식
- nfs.server, nfs.path로 실제 외부 스토리지를 가리킴
6. 로컬 PV(local)와 nodeAffinity가 필요한 이유
노드의 로컬 디스크를 PV로 쓰는 경우도 있다.
이때는 “특정 노드에 고정”되어야 하므로 nodeAffinity가 필요하다.
- 로컬 볼륨은 한 노드에만 존재
- 파드가 다른 노드로 가면 볼륨을 못 찾는다
- 따라서 레이블로 노드를 식별하고, PV에 nodeAffinity를 걸어야 한다
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01
spec:
capacity:
storage: 50Mi
accessModes:
- ReadWriteOnce
local:
path: /volumes/pv01
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kiamol
operator: In
values:
- ch05- local.path는 노드 로컬 경로
- nodeAffinity로 “이 PV는 특정 노드에서만 유효”하다고 선언
6-1) hostPath vs Local PV 차이
| 목적 | 단순히 노드 경로를 Pod에 연결 | 노드 로컬 디스크를 “PV로 추상화” |
| 쿠버 스토리지 모델(PV/PVC) 사용 | ❌ 안 씀 | ✅ PV/PVC 사용 |
| 스케줄링 제어 | 없음 | nodeAffinity로 노드 고정 |
| 운영환경 사용 | 거의 안 함 (위험) | 제한적으로 사용 가능 |
| 보안 | 루트 노출 위험 큼 | PV로 관리되므로 상대적으로 안전 |
| 가장 적합한 용도 | 실습/디버깅 | Stateful workload + 로컬 SSD |
7. PersistentVolumeClaim(PVC): 파드가 스토리지를 요청하는 방식
PVC는 파드가 사용할 스토리지의 추상이다.
- 애플리케이션 입장에서 “스토리지를 요청”
- 요구조건이 일치하는 PV와 바인딩됨
- 상세한 볼륨 구현은 PV에게 맡김
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 40Mi
storageClassName: ""PVC가 지정하는 것
- 접근 유형(accessModes)
- 요청 용량(requests.storage)
- 스토리지 유형(storageClassName)
스토리지 유형을 지정하지 않으면
- 존재하는 PV 중 요구사항과 일치하는 것을 찾아 바인딩한다
7-1) PV와 PVC는 1:1 관계
- PV와 PVC는 1:1로 바인딩된다
- 하나의 PV는 다른 PVC와 추가로 연결 불가
7-2) ReadWriteOnce(RWO)
- 뜻: 하나의 노드에서만 Read/Write 가능
- PVC를 여러 Pod가 “참조”할 수는 있다
- 하지만 동시에 사용하려면 그 Pod들이 같은 Node에 있어야 한다
- 예시
- ReplicaSet이 같은 노드에 여러 Pod를 올리면 가능
- 하지만 다른 노드로 분산되면 불가능
7-3) ReadOnlyMany (ROX)
- 뜻: 여러 Pod가 동시에 Read 가능
- PVC 하나 ← 여러 Pod (읽기 전용)
- 예시
- Config 공유
- 정적 파일 제공
7-4) ReadWriteMany (RWX)
- 여러 Pod가 동시에 Read/Write 가능
- 예시
- NFS
- EFS
- CephFS
7-5) PVC에서는 40Mi를 요청했는데, 50Mi로 나오는 이유

PVC는 “요청 용량”을 쓰고, PV는 “실제 제공 용량(capacity)”을 가진다.
- PVC에서 40Mi를 요청해도
- 바인딩된 PV가 50Mi면, 화면/조회에서 50Mi가 보일 수 있다
- 이 값은 PV의 capacity를 의미한다
8. 정적 프로비저닝 vs 동적 프로비저닝
8-1) 정적 프로비저닝(Static)
- PV를 명시적으로 생성해야 함
- 어떤 클러스터에서도 동작하는 가장 기본 방식
8-2) 동적 프로비저닝(Dynamic)
- PVC를 생성하면 조건에 맞는 PV를 “자동으로 생성”
- 클러스터마다 기본 스토리지 유형(StorageClass)이 다를 수 있음
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc-dynamic
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100MiPVC만 만들었을 때 “클러스터마다” 달라질 수 있는 이유
- 기본 StorageClass(프로비저너)가 환경마다 다름
- Docker Desktop 기본 스토리지 유형: hostPath
- AKS: AzureFiles
- k3s: hostPath (파드 생성 시점에 PV 생성되는 식으로 동작)
8-3) StorageClass
StorageClass는 “이 스토리지가 어떻게 만들어지고 관리되는지”를 정의한다.
핵심 필드 3가지
- provisioner
- PV가 필요할 때 PV를 만드는 주체
- 플랫폼마다 다름 (예: AKS 기본은 AzureFiles가 프로비저닝)
- reclaimPolicy
- PVC가 삭제되었을 때 실제 볼륨을 어떻게 처리할지
- 삭제(Delete) 또는 유지(Retain) 등
- volumeBindingMode
- Immediate: PVC 생성 즉시 PV 생성/바인딩
- WaitForFirstConsumer: 해당 PVC를 사용하는 Pod가 생성될 때 PV 생성/바인딩
8-4) 기본 StorageClass 복제해서 커스텀 StorageClass 만들기
쿠버네티스는 기본 스토리지 클래스를 label이 아니라 annotation으로 표시한다.
그래서 JSONPath로 기본 StorageClass를 찾아 복제하는 흐름이 필요하다.
#!/bin/sh
# default storageclass를 찾고, spec을 JSON으로 저장
kubectl get sc $(kubectl get storageclass \
-o jsonpath="{range .items[?(@.metadata.annotations.storageclass\.kubernetes\.io/is-default-class == 'true')]}{.metadata.name}") \
$(kubectl get storageclass -o jsonpath="{range.items[?(@.metadata.annotations.storageclass\.beta\.kubernetes\.io/is-default-class == 'true')]}{.metadata.name}") \
-o json > defaultStorageClass.json
# 복제 스크립트를 실행할 pod 배포
kubectl apply -f storageClass/clone-storageClass-script.yaml
# 준비될 때까지 대기
kubectl wait --for=condition=Ready pod/clone-sc
# default sc spec을 pod로 복사
kubectl cp defaultStorageClass.json clone-sc:/defaultStorageClass.json
# 복제 스크립트 실행 -> 커스텀 SC JSON 생성
kubectl exec clone-sc -- /scripts/duplicate-default-storage-class.sh > kiamolStorageClass.json
# 적용
kubectl apply -f kiamolStorageClass.json
# 복제용 pod 삭제
kubectl delete -f storageClass/clone-storageClass-script.yaml이 과정을 거치면
- 클러스터 기본 스토리지 유형과 동일한 동작을 하는
- kiamol 같은 사용자 정의 StorageClass를 만들 수 있다
커스텀 StorageClass를 사용하는 PVC 예시
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc-kiamol
spec:
accessModes:
- ReadWriteOnce
storageClassName: kiamol
resources:
requests:
storage: 100Mi- DB 파드가 새 PVC를 쓰도록 업데이트하는 경우
- 새로 생성된 PV에 연결되기 때문에 이전 데이터는 잃는다
- 다만 기존 볼륨(PV)은 남아있을 수 있고, 다시 연결하면 데이터 복구 가능
8-5) PVC/PV가 없을 때 Pending이 되는 이유
- PVC가 생성되었는데 바인딩될 PV가 없으면 PVC는 Pending
- 그 PVC를 참조하는 Pod도 같이 Pending이 될 수 있다
8-6) 운영에서 “노드에 로그인 못하는 상황”과 우회 방법
실제로 노드에 직접 로그인할 권한이 없는 경우가 많다.
이럴 때 hostPath로 루트 디렉터리를 마운트한 sleep 파드를 띄워서
- 원하는 디렉터리를 만들거나
- 노드의 파일을 확인하는 식으로 우회할 수 있다
9. 연습문제(메모만)
9-1) nginx 캐시 디렉터리 이슈와 해결
nginx에서 캐시 경로를 지정했는데 디렉터리가 없으면 실행이 실패한다.
- 해결: hostPath + DirectoryOrCreate 로 디렉터리를 보장
실습에서 사용한 proxy + nginx 캐시 볼륨 구성 예시
apiVersion: v1
kind: Service
metadata:
name: todo-proxy-lab
labels:
app: todo-proxy-lab
spec:
ports:
- port: 8082
targetPort: 80
selector:
app: todo-proxy-lab
type: LoadBalancer
---
apiVersion: v1
kind: ConfigMap
metadata:
name: todo-proxy-lab-configmap
data:
nginx.conf: |-
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
proxy_cache_path /data/nginx/cache levels=1:2 keys_zone=STATIC:10m inactive=24h max_size=1g;
server {
listen 80 default_server;
listen [::]:80 default_server;
location / {
proxy_pass http://todo-web-lab;
proxy_set_header Host $host;
proxy_cache STATIC;
proxy_cache_valid 200 1d;
add_header X-Cache $upstream_cache_status;
add_header X-Host $hostname;
}
}
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: todo-proxy-lab
labels:
app: todo-proxy-lab
spec:
selector:
matchLabels:
app: todo-proxy-lab
template:
metadata:
labels:
app: todo-proxy-lab
spec:
containers:
- image: nginx:1.17-alpine
name: nginx
ports:
- containerPortriPort: 80
name: http
volumeMounts:
- name: config
mountPath: "/etc/nginx/"
readOnly: true
- name: cache-volume
mountPath: /data/nginx/cache
volumes:
- name: config
configMap:
name: todo-proxy-lab-configmap
- name: cache-volume
hostPath:
path: /volumes/nginx/cache
type: DirectoryOrCreate추가로 겪은 상황
- 이미 8080 포트를 쓰는 컨테이너가 실행 중이었고, 종료하니 해결됨
9-2) Mac(Apple Silicon)에서 앱 이미지 아키텍처 문제
실습 중 kiamol/ch04-todo-list 이미지가 amd64용으로 빌드되어 있어
Mac M1/M2/M3(arm64)에서 SQLite 네이티브 라이브러리가 동작하지 않는 문제가 발생했다.
- 즉, 애플리케이션 레이어에서 에러가 발생
- 해결 방향: 책 강의에서 사용한 PostgreSQL 구성을 재사용
아래는 PostgreSQL + 웹 구성(Secret/ConfigMap/PVC 포함) 예시
# PostgreSQL PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
---
# PostgreSQL Secret
apiVersion: v1
kind: Secret
metadata:
name: todo-db-secret
type: Opaque
stringData:
POSTGRES_PASSWORD: kiamol-2*2*
---
# PostgreSQL Service
apiVersion: v1
kind: Service
metadata:
name: todo-db
spec:
ports:
- port: 5432
targetPort: 5432
selector:
app: todo-db
type: ClusterIP
---
# PostgreSQL Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: todo-db
spec:
selector:
matchLabels:
app: todo-db
template:
metadata:
labels:
app: todo-db
spec:
containers:
- name: db
image: postgres:11.6-alpine
env:
- name: POSTGRES_PASSWORD_FILE
value: /secrets/postgres_password
volumeMounts:
- name: secret
mountPath: "/secrets"
- name: data
mountPath: /var/lib/postgresql/data
volumes:
- name: secret
secret:
secretName: todo-db-secret
defaultMode: 0400
items:
- key: POSTGRES_PASSWORD
path: postgres_password
- name: data
persistentVolumeClaim:
claimName: postgres-pvc
---
# Web ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: todo-web-lab-config
data:
config.json: |-
{
"ConfigController": {
"Enabled" : true
},
"Database" : {
"Provider" : "Postgres"
}
}
---
# Web Secret
apiVersion: v1
kind: Secret
metadata:
name: todo-web-lab-secret
type: Opaque
stringData:
secrets.json: |-
{
"ConnectionStrings": {
"ToDoDb": "Server=todo-db;Database=todo;User Id=postgres;Password=kiamol-2*2*;"
}
}
---
# Web Service
apiVersion: v1
kind: Service
metadata:
name: todo-web-lab
spec:
ports:
- port: 80
targetPort: 80
selector:
app: todo-web-lab
type: ClusterIP
---
# Web Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: todo-web-lab
spec:
selector:
matchLabels:
app: todo-web-lab
template:
metadata:
labels:
app: todo-web-lab
spec:
containers:
- name: web
image: kiamol/ch04-todo-list
env:
- name: ASPNETCORE_ENVIRONMENT
value: Test
volumeMounts:
- name: config
mountPath: "/app/config"
readOnly: true
- name: secret
mountPath: "/app/secrets"
readOnly: true
volumes:
- name: config
configMap:
name: todo-web-lab-config
items:
- key: config.json
path: config.json
- name: secret
secret:
secretName: todo-web-lab-secret
defaultMode: 0400
items:
- key: secrets.json
path: secrets.json메모
- PostgreSQL은 설정을 json으로 둬야 해서 ConfigMap/Secret을 따로 만들고 적용했다
결과

10. DB를 쿠버네티스로 옮겨야 하는가?
결론부터 말하면, 데이터 관리는 쿠버에서 쉬운 일이 아니다.
- stateful application은 운영 난이도를 높인다
- 백업/스냅샷/복원 같은 운영 기능이 중요해지는데, 이걸 직접 구성해야 한다
클라우드에서는 매니지드 DB가 이 부담을 상당히 줄여준다.
- 대신 비용이 늘 수 있다
그래도 “전체 스택을 쿠버 매니페스트로 통일”하고 싶다면
- 컨테이너 플랫폼을 위해 만들어진 현대식 DB도 선택지가 된다
- TiDB
- CockroachDB
'Kubernetes' 카테고리의 다른 글
| Kubernetes Network (1) | 2026.01.18 |
|---|---|
| Kubernetes Pod와 Deployment (0) | 2026.01.04 |